The following model aims to evaluate the extent to which the canon privileges certain factors (e.g., age, gender, setting). Why? The model should evaluate the extent to which a text is in dialogue with other texts appearing in the canon (and thus operates as a centripetal force reinforcing the idea of the canon as a coherent network) and vice versa whether it is original enough and thus articulates a valuable intervention to the field of Italian literature. The data set has been split into train (size=0.8) and test (size=0.2).
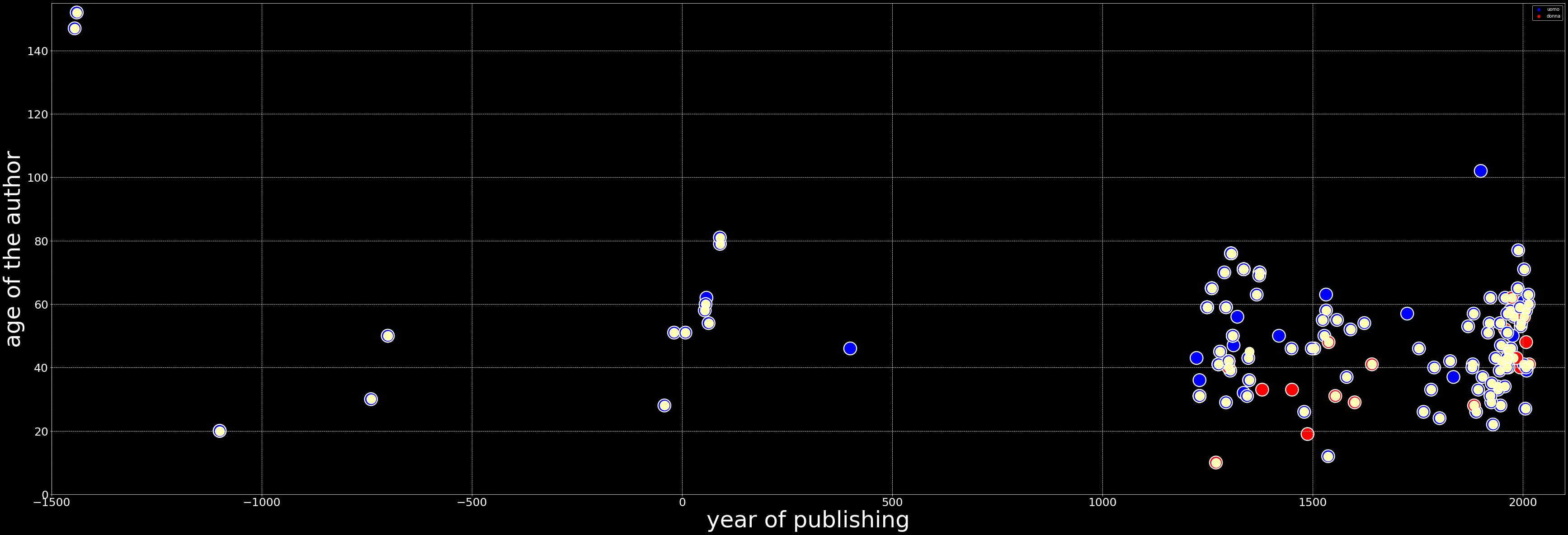
My baseline model predicts the age of the author of a particular text (i.e. a numerical value) based on the year in which the text was published and the sex of the author. Adding a third factor such as the year in which the author was born decreases the mean squared error quite significantly. Indeed, the model performs better than one attempting to predict the age of the author throuhg a logistic regression.
#drop rows where age of the author is less than 15 or older than 100
df = df.loc[df['age'] > 15]
df = df.loc[df['age'] < 100]
Convert gender values into binary 0 and 1
dummies = pd.get_dummies(df['gender'])
df = pd.concat((df, dummies), axis=1)
df.drop(['gender'], axis= 1)
df.drop(['uomo'], axis= 1)
df = df.rename(columns={'donna': 'sex'})
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.linear_model import LinearRegression
y = df['age']
x = df[['year', ‘sex']]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=140, random_state=4)
lreg = LinearRegression()
lreg.fit(x_train, y_train)
y_pred= lreg.predict(x_test)
MSE = mean_squared_error(y_test, y_pred)
print(y_pred)
print(MSE)
[48.68616568 48.61149332 47.81498816 48.47459399 49.03463669 40.48465159 40.95757653 73.62673354 40.48465159 40.94513114 48.2879131 48.2879131 40.54687856 40.70866867 82.83632447 40.45976081 41.50517383 39.91216351 47.81498816 49.04971827 48.12612299 46.86913828 41.40561069 48.81061961 48.12612299 49.59467938 52.21084813 48.2879131 49.23376298 64.8153952 43.09818415 48.58660253 49.03463669 45.12678324 43.82265315 45.52503582 40.39753384 49.3706623 40.67133249 63.79487296 41.34338372 48.47723018 40.1112898 49.23376298 48.66127489 42.73726775 48.73594725 40.98246732 48.2879131 40.98246732 52.58420992 64.24290711 45.89839761 48.66127489 41.48028305 49.3706623 73.62673354 52.21084813 39.98683587 65.43766485 49.23376298 42.07766192 48.66127489 48.73594725 43.39950978 49.59467938 39.84993654 47.81498816 40.55932395 48.2879131 40.2979707 43.68575382 49.24884456 40.6464417 41.64207316 40.69622328 74.12454927 49.3706623 39.9246089 39.99928126 48.73594725 78.6048908 46.27175941 49.59467938 65.15142081 47.82743355 48.81061961 48.98485511 40.08639901 46.19708705 46.49577648 39.9246089 39.94949969 48.86040118 47.96696907 48.61149332 42.65015 40.44731541 40.17351676 45.23879178 40.37264306 40.2855253 64.21801633 49.03463669 40.68377788 51.21521668 40.8331226 39.98683587 48.73594725 41.00735811 48.73594725 48.61149332 43.31239203 40.49709699 39.86238194 48.66127489 45.84861604 41.21892979 40.4722062 43.44665516 47.81498816 49.87111422 63.79487296 47.90210591 40.77089564 48.98485511 64.19312554 59.93680108 50.33159376 49.3706623 48.66127489 40.75845024 45.84861604 48.73594725 48.81061961 48.73594725 49.03463669 41.51761922 41.26871136 49.59467938]
MSE: 317.9869089456771
y = df['age']
x = df[['year', ‘sex’, ‘birth’]]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=140, random_state=4)
lreg = LinearRegression()
lreg.fit(x_train, y_train)
y_pred= lreg.predict(x_test)
MSE = mean_squared_error(y_test, y_pred)
print(y_pred)
print(MSE)
[ 33. 42. 70. 42. 53. 31. 24. 33. 50. 37. 71. 42. 22. 45. 26. 70. 10. 46. 51. 31. 60. 46. 42. 79. 42. 42. 31. 62. 81. 65. 71. 42. 58. 76. 54. 56. 46. 52. 58. 43. 39. 48. 147. 54. 50. 39. 59. 71. 65. 58. 71. 46. 34. 43. 40. 57. 43. 55. 37. 59. 41. 70. 51. 27. 26. 42. 20. 71. 41. 30. 43. 28. 26. 54. 55. 31. 50. 51. 58. 59. 76. 63. 28. 34. 71. 71. 41. 65. 31. 36. 65. 45. 40. 59. 41. 77. 62. 45. 29. 57. 35. 40. 152. 59. 56. 47. 54. 29. 50. 20. 12. 50. 28. 40. 59. 40. 42. 62. 53. 41. 76. 51. 54. 69. 50. 40. 29. 76. 45. 46. 43. 41. 60. 33. 63. 31. 70. 46.]
MSE: 0.586956521739123
y = df['sex']
columns = [['age'], ['year'], ['age', 'year']]
for x in columns:
x = df[x]
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=140, random_state=4)
lreg = LogisticRegression()
lreg.fit(x_train, y_train)
y_pred= lreg.predict(x_test)
MSE = mean_squared_error(y_test, y_pred)
print(y_pred)
print(MSE)
[0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
MSE: 0.1
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
MSE: 0.10714285714285714
[0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0]
MSE: 0.1357142857142857
The genre, place, the dictionary of each text, its CL index, the author's education/degree, social class
At the moment, converting the genres and settings into numerical values only increases the mean squared error since there is so much variance.
dumy = pd.get_dummies(df['genre'])
df = pd.concat((df, dummies), axis=1)
dumx = pd.get_dummies(df['place'])
df = pd.concat((df, dumx), axis=1)
df.columns
Index(['index', 'name', 'title', 'year', 'age', 'birth', 'place', 'gender',
'genre', 'Agrigento', 'Alcamo', 'Antioch', 'Arezzo', 'Assisi', 'Asti',
'Betsaida ', 'Bologna', 'Brescia', 'Calcutta', 'Capua', 'Catania',
'Certaldo', 'Chianciano Terme', 'Collodi', 'Egypt', 'Ephraim',
'Ferrara', 'Firenze', 'Genova', 'Ionia', 'Jerusalem',
'Kingdom of Judah', 'Lentini', 'Lucca', 'Mantova', 'Matera', 'Milano',
'Montepulciano', 'Napoli', 'Palermo', 'Parigi', 'Pistoia', 'Racalmuto',
'Ravenna', 'Recanati', 'Reggio Emilia', 'Roma',
'San Pellegrino, Belluno', 'San Remo', 'Santo Stefano Belbo', 'Siena',
'Siracusa', 'Sorrento', 'Sulmona', 'Tarsus', 'Thagaste', 'Todi',
'Torino', 'Trieste', 'Venezia', 'Verona', 'Zante', 'sex', 'uomo',
'film', 'poetry', 'prose', 'prose fiction', 'theology', 'theory'],
dtype='object')